SEO Log File Analysis on a Large Scale with Python & MySQL

Working on big websites containing millions of pages is challenging to track bot's behavior on your websites. The access log file is the best source for getting this information about the bots and what they visit every day for better understanding and best results for your SEO.
What Is the Access Log File?
Access log files are files on your server that store every visit from bots or real users on your website, and it is real-time tracking where you can see the most visited pages on your website, a time, IP, and many other details.
Where Can I Find My Access Log Files for SEO
If you are running your website on a Linux and Apache server, you can find them under /var/log/apache2
How Access Log Files Are Stored on the Server
By default, the Apache server rotates the access log files and compresses them in GZ format to save space on the server.
How Does the Access Log File Content Look Like
This is a sample from the Apache access log file with the default format
66.249.66.73 - - [25/Dec/2021:21:55:06 +0200] "GET /coins/win/ HTTP/1.1" 200 6383 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)You will find thousands like the above line in your log files, and in this tutorial and for SEO purposes, we will learn how to read these files to track the behavior of Google bots on your website for each bot and page type. And you can build your dashboard using your preferred tool like Google Data Studio, Tableau, and Power BI.
Download Access Log Files From the Server
The first step is to get all the access log files from the server. If your server is running on Apache, you can find them under /var/log/apache2.
Here we will use the compressed files and leave the .log files since they are not ready yet and still the Apache is collecting logs and writing into them.
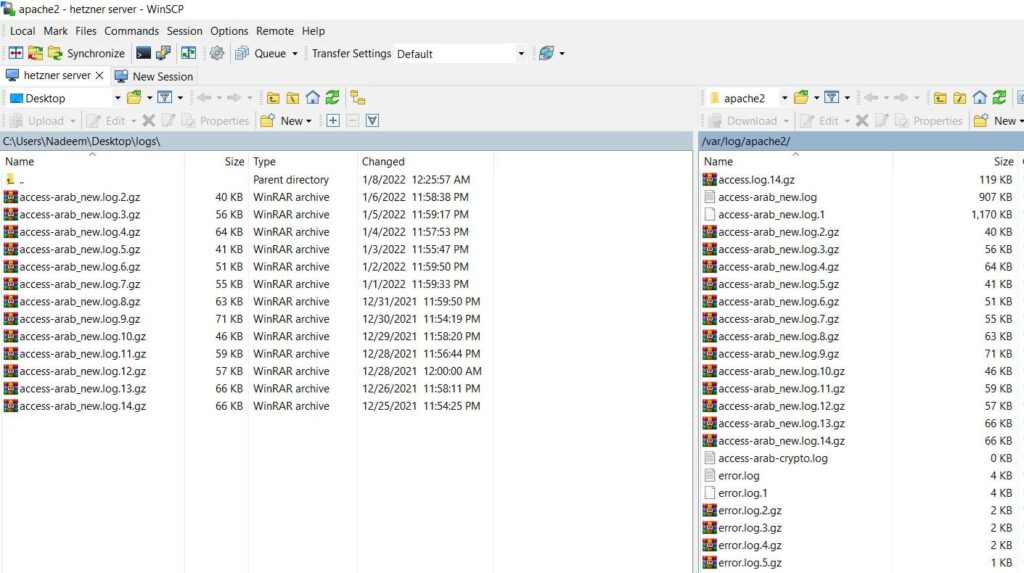
The second step is to locate all your compress logs in a folder to access them through a Python script.
Python Libraries
We will be using the below Python libraries to do all the work for our SEO log file analysis task
import pandas as pd
import glob
from urllib.parse import unquote
from collections import Counter
import matplotlib.pyplot as plt
import re
import gzip
from datetime import datetime
import mysql.connector
from tqdm.notebook import tqdmGet all the files with .gz extension
logs_gz = glob.glob("source/*.gz")Define a name for the final text file that we will use after extracting all the compressed files.
log_text_file_name = "source/logs.txt"Extract the compressed files and append them to a new text file
for log_gz in logs_gz:
with gzip.open(log_gz, 'rb') as f_in:
with open(log_text_file_name, 'a') as f_out:
log_file_lines = f_in.readlines()
for line in log_file_lines:
f_out.write(str(line) + "\n")
f_in.close()
f_out.close()Define a domain name to use in the URLs. Usually, the log files remove the domain name and include only the page's path after the TLD.
domain = "https://www.arabcryptocap.io"Parse the final text file and import its content to a Pandas data frame, thanks to Stack Overflow
df = pd.read_csv(log_text_file_name,
sep=r'\s(?=(?:[^"]*"[^"]*")*[^"]*$)(?![^\[]*\])',
engine='python',
usecols=[0, 3, 4, 5, 6, 7, 8],
names=['ip', 'time', 'request', 'status', 'size', 'referer', 'user_agent'],
na_values='-',
header=None
)The data frame looks like this
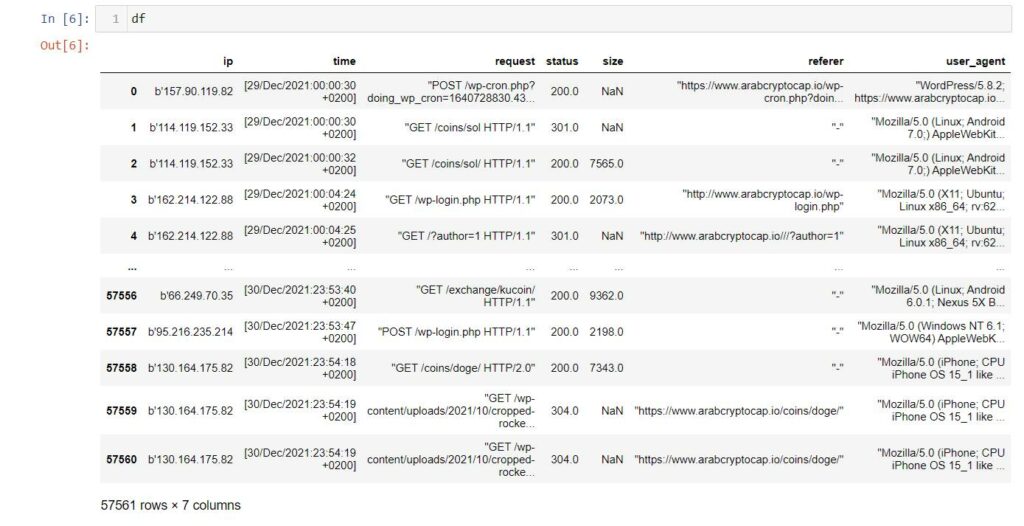
As you can see, some values need to be formated, like date, time, and requests. We will do that using the below lines.
Requests
def clean_reuqest(request, domain):
request = unquote(str(request).replace("POST ","").replace("GET ",""))
request_url = domain + request.split()[0].replace('"',"").replace("[","").replace("]","").replace("[","").replace("]","")
return request_url
df["request"] = df["request"].apply(lambda request : clean_reuqest(request, domain))Date and Time
def get_time(time):
if str(time) != "None":
time = str(time).split(" +")[0].replace("[","").replace("]","")
date_obj = datetime.strptime(time, "%d/%b/%Y:%H:%M:%S")
final_time = date_obj.strftime("%m/%d/%Y :%H:%M:%S")
return final_time
df["time"] = df["time"].apply(lambda time : get_time(time))
def get_date(time):
if str(time) != "None":
datetime_object = datetime.strptime(time, '%m/%d/%Y :%H:%M:%S')
request_date = datetime_object.strftime("%d-%m-%Y")
return request_date
df["Date"] = df["time"].apply(lambda time : get_date(time))The above formats for the date and time can be used in Google Sheet. We will change them later for MySQL databases.
IP
df["ip"] = df["ip"].apply(lambda ip : str(ip).replace("b'",""))User Agents
df["user_agent"] = df["user_agent"].apply(lambda ua : str(ua).replace('"',""))Filtering Google Bots From Access Log File
In this tutorial, we will work only on Google bots for our SEO log file analysis task and ignore the rest of the bots.
To do that, we will get the requests with IPs starting with 66.
def get_bot_type(ip):
if re.match("^66.", ip):
return "Google Bot"
else:
return "Other Bot"
df["Bot Type"] = df["ip"].apply(lambda x : get_bot_type(x))You can find the whole list of Google Bots IPs in JSON format from this link.
We will check every request and define Google Bot type from the below list.
Google bots and their user agents strings
| Google Bot Name | Full User-Agent String |
| Googlebot Image | Googlebot-Image/1.0 |
| Googlebot Desktop | Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) |
| Googlebot Smartphone | Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/W.X.Y.Z Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) |
| AdSense | Mediapartners-Google |
You can find the complete list of Google Bots user agents from here
def get_google_bot_type(ua):
ua = str(ua)
if ua.find("APIs-Google") > -1:
return "APIs Google"
elif ua.find("Mediapartners-Google") > -1:
return "Mediapartners Google"
elif ua.find("AdsBot-Google-Mobile") > -1:
return "AdsBot Google Mobile"
elif ua.find("AdsBot-Google") > -1:
return "AdsBot Google"
elif ua.find("Googlebot-Image") > -1:
return "Googlebot Image"
elif ua.find("Googlebot-News") > -1:
return "Googlebot News"
elif ua.find("Googlebot-Video") > -1:
return "Googlebot Video"
elif ua.find("AdsBot-Google-Mobile-Apps") > -1:
return "AdsBot-Google-Mobile-Apps"
elif ua.find("FeedFetcher-Google") > -1:
return "FeedFetcher Google"
elif ua.find("Google-Read-Aloud") > -1:
return "Google Read Aloud"
elif ua.find("DuplexWeb-Google") > -1:
return "DuplexWeb-Google"
elif ua.find("Google Favicon") > -1:
return "Google Favicon"
elif ua.find("googleweblight") > -1:
return "Google Web Light"
elif ua.find("Storebot-Google") > -1:
return "Storebot Google"
elif ua.find("Googlebot/2.1") > -1 and ua.find("Mobile") > -1:
return "Google Bot Mobile"
elif ua.find("Googlebot/2.1") > -1:
return "Google Bot Desktop"
elif ua.find("Chrome-Lighthouse") > -1:
return "Chrome Lighthouse"
else:
return "Other"
df = df.loc[df["Bot Type"] == "Google Bot"]
df["Google Bot Type"] = df["user_agent"].apply(lambda x : get_google_bot_type(x))Now we are done preparing the data, and you can export it into a CSV file and see the results on Google Sheets to start analyzing the behavior of Google Bots and their effect on your SEO results.
Before that, we will analyze our script using the Matplotlib library.
Top HTTP Status Codes
status_codes_list = Counter(df["status"].to_list()).most_common()
status_code_group = []
status_code_count = []
for status_item in status_codes_list:
status_code_group.append(str(status_item[0]))
status_code_count.append(status_item[1])
plt.bar(status_code_group, status_code_count)
plt.xlabel("Request Group")
plt.ylabel("Number of Requests")
plt.show()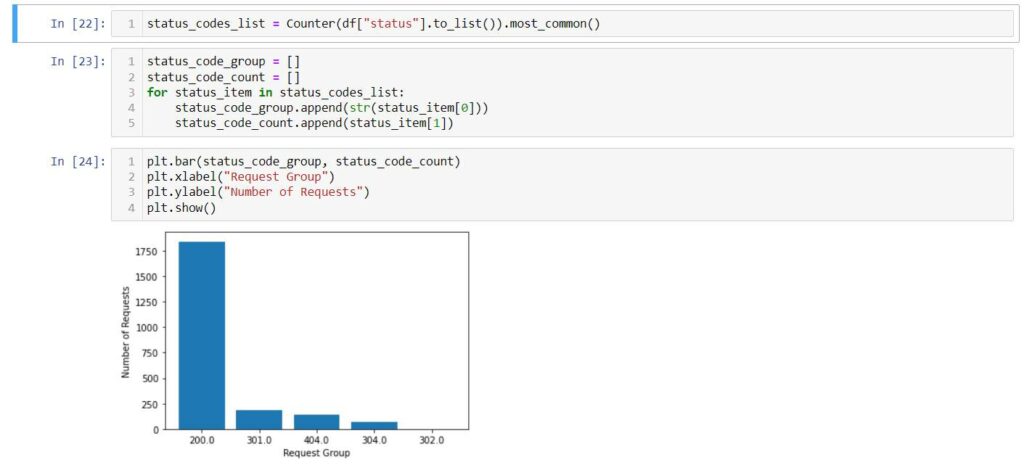
Top Google Bots
bot_type = Counter(df["Google Bot Type"].to_list()).most_common()
bot_name_list = []
bot_value_list = []
for bot_item in bot_type:
bot_name_list.append(bot_item[0])
bot_value_list.append(bot_item[1])
plt.bar(bot_name_list,bot_value_list)
plt.ylabel("Number of Requests")
plt.xlabel("Google Bot Type")
plt.xticks(rotation=45)
plt.show()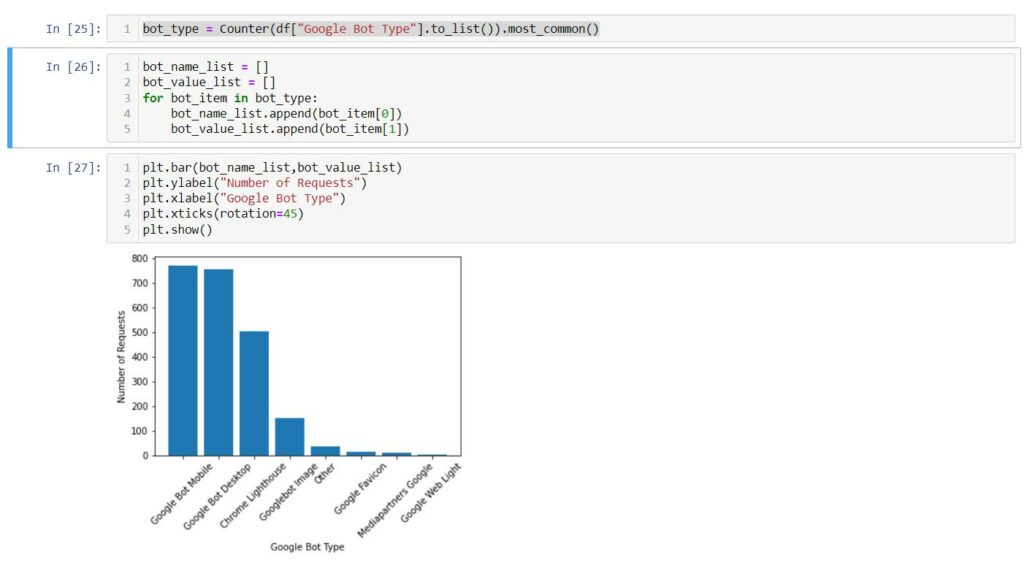
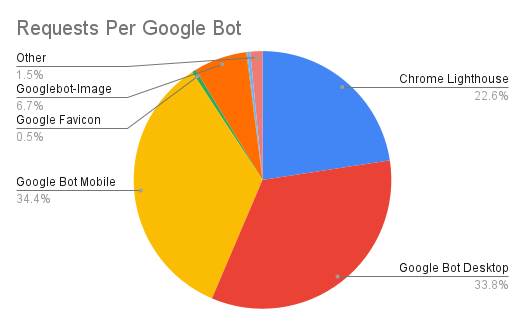
We can see that most of the requests are from Google Smartphone and Desktop bots.
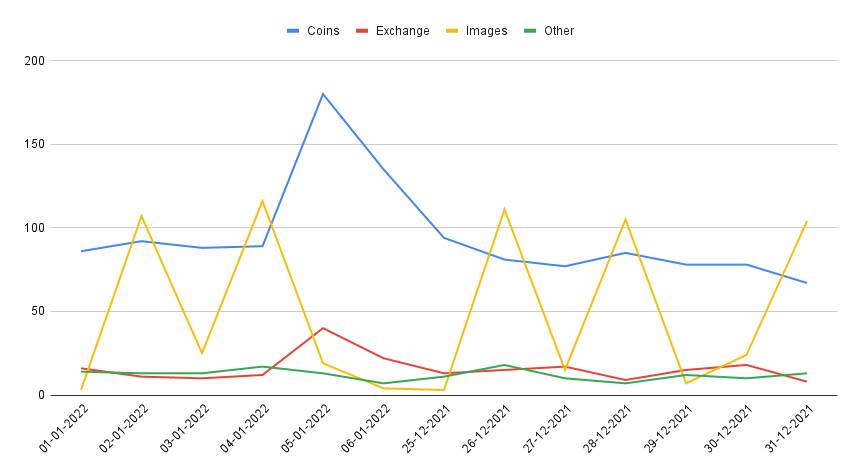
Define The Page Type
Now I will define a page type for each request from Google bots, and this will help me see if Google crawls the content pages or categories or if I have some pages that are not appropriately linked from the homepage.
In this example, I have three types of pages
- Coins
- Exchanges
- Images (Files)
def get_page_type(page):
if page.find("/coins/") > -1:
return "Coins"
elif page.find("/exchange/") > -1:
return "Exchange"
elif page.find("wp-content") > -1:
return "Images"
else:
return "Other"
df["Page Type"] = df["request"].apply(lambda page : get_page_type(page))Then I will get the page name
def get_page_name(row):
if row["Page Type"] == "Coins" or row["Page Type"] == "Exchange":
return row["request"].split("/")[4]
elif row["Page Type"] == "Images":
return "Images"
else:
return "No Page"
df["Page Name"] = df.apply(lambda row : get_page_name(row),axis=1)This will help me analyze the content and keywords to see a correlation between the number of requests from Google bots and traffic.
Save the results in CSV format
df.to_csv("results/google_logs.csv", index=False)Now you can import the data into Google Sheets and start analyzing the requests per page type and Google bot.
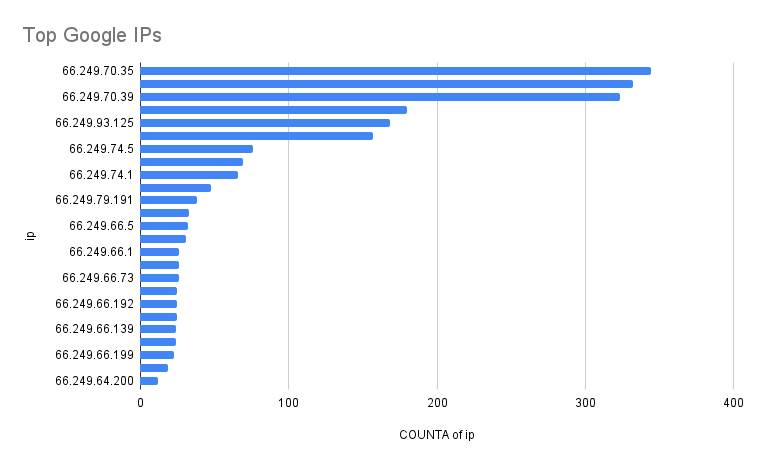
Top Google Bots IPs
Requests Per Google Bot
Requests Per Page Type
You can find the full analysis on this Google sheet
Backup Google Access Logs Data on MySQL Database
If you plan to do SEO log file analysis every day, storing the data in a MySQL database is better. It is reliable and faster to connect the MySQL database to Google Data Studio or Tableau.
First, we will create our database and create a table with the needed fields.
CREATE TABLE `logs` (
`id` int NOT NULL AUTO_INCREMENT,
`time` datetime NOT NULL,
`date` date NOT NULL,
`ip` text NOT NULL,
`url` text NOT NULL,
`status_code` text NOT NULL,
`size` int NOT NULL,
`user_agent` text NOT NULL,
`bot_type` text NOT NULL,
`google_bot_type` text NOT NULL,
`page_type` text NOT NULL,
`page_name` text NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=MyISAM AUTO_INCREMENT=2238 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci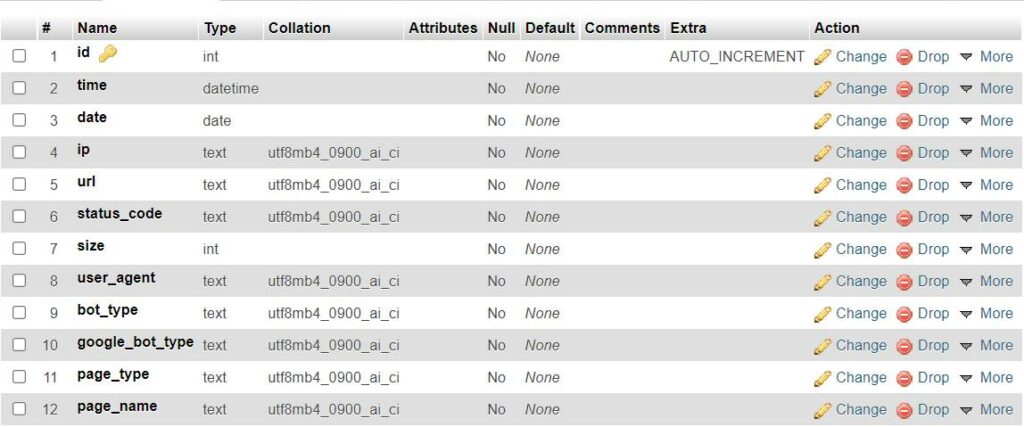
Connect to the database through our Python script
mydb = mysql.connector.connect(
host="localhost",
user="root",
password="root",
database="google_logs"
)
mycursor = mydb.cursor()Change the data formats for a valid MySQL date and time
def correct_date(date):
date_obj = datetime.strptime(date, "%d-%m-%Y")
return date_obj.strftime("%Y-%m-%d")
def correct_time(time):
time_obj = datetime.strptime(time, "%m/%d/%Y :%H:%M:%S")
return time_obj.strftime("%Y-%m-%d %H:%M:%S")Define a function to insert the data into the database
def mysql_insert(request, mycursor):
time = correct_time(request["time"])
date = correct_date(request["Date"])
ip = request["ip"]
url = request["request"]
status_code = request["status"]
size = request["size"]
user_agent = request["user_agent"]
bot_type = request["Bot Type"]
google_bot_type = request["Google Bot Type"]
page_type = request["Page Type"]
page_name = request["Page Name"]
sql = f'insert into logs (`time`,`date`,`ip`,`url`,`status_code`,`size`,`user_agent`,`bot_type`,`google_bot_type`,`page_type`,`page_name`) values ("{time}","{date}","{ip}","{url}","{status_code}","{size}","{user_agent}","{bot_type}","{google_bot_type}","{page_type}","{page_name}")'
mycursor.execute(sql)
mydb.commit()Loop over the data frame and insert the data into the database
for index, request in tqdm(df.iterrows()):
mysql_insert(request, mycursor)Now we have all the requests stored in a MySQL database
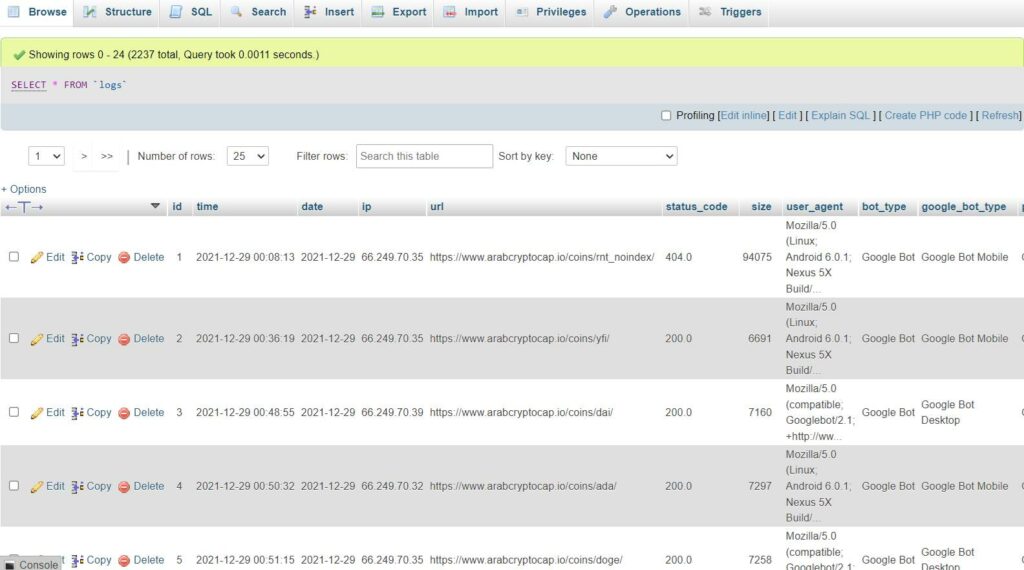
Quick Tips to Store Google SEO Logs Into MySQL Database
- Make sure to monitor the space on your server after inserting the data. Sometimes it will exceed 1GB each day.
- Always remove the data once you are done with the Analysis. You can do this every 2 or 3 weeks to make a room in your server for fresh data.
Related Posts




About the Author
